

Golang核心特性
1.并发编程
不同于传统的多进程或多线程,golang的并发执行单元是一种称为goroutine的协程。其在语言级别提供关键字:
- go——用于启动协程。
- chan——golang中用于并发的通道,用于协程的通信。
- select——golang提供的多路复用机制。
- close()——golang的内置函数,可以关闭通道。
- sync——golang标准库之一,提供锁。
协程经常被理解为轻量级线程,一个线程可以包含多个协程,共享堆不共享栈。协程间一般由应用程序显式实现调度,上下文切换无需下到内核层,高效不少。
协程间一般不做同步通讯,而golang中实现协程间通讯有两种:
- 共享内存型,即使用全局变量+mutex锁来实现数据共享;
- 消息传递型,即使用一种独有的channel机制进行异步通讯。
高并发是Golang最大的亮点。
2.内存管理
堆内存
Go 的内存分配是参考 TcMalloc 实现的,TCMalloc 的核心思想是:
- 按照一组预置的大小规格将内存页划分成块,然后把不同规格的内存块放入对应的空闲链表中;程序申请内存时,分配器会根据其内存大小找到最匹配的规格,从对应空闲链表分配一个或若干个内存块。
- Go 1.16 runtime包,给出了67种大小规格,最小8B,最大32KB。
Go 的内存管理是一个金字塔结构,层次如下:
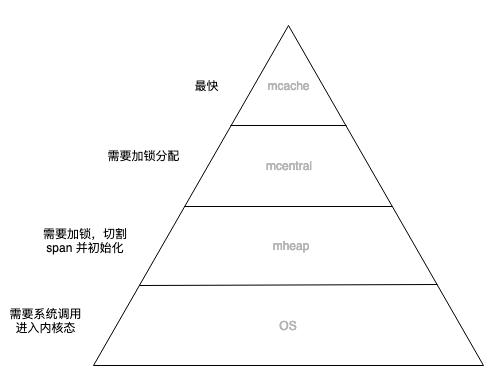
接下来逐个分析一下 Go 各个内存分配器的大致结构:
- mspan —— 是 Go 内存管理的基本单元,若干个连续的 page 组成一个 mspan。(Go 的一个 page 为 8KB)
源码文件路径:runtime/mheap.go Line:316
type mspan struct {
next *mspan // 链表下一个span地址
prev *mspan // 链表前一个span地址
list *mSpanList // 链表地址 用于调试
startAddr uintptr // 该span在arena区域的起始地址
npages uintptr // 该span占用arena区域page的数量
manualFreeList gclinkptr // 空闲链表
freeindex uintptr // 扫描页中空闲对象的初始索引(表明freeindex之前的都被使用)
nelems uintptr // 管理的对象(块)个数,也即有多少个块可供分配。
allocCache uint64 // allocBits 的补码,缓存freeindex开始的bitmap,可以用于快速查找内存中未被使用的内存。
allocBits *gcBits // 该mspan中对象分配位图,每一位代表一个块是否已分配。
allocCount uint16 // 已分配的对象的个数
spanclass spanClass // sizeclass表中的classId
needzero uint8 // 分配之前需要置零
elemsize uintptr // sizeclass表中的对象大小,也即块大小
unusedsince int64 // 空闲状态开始的纳秒值时间戳,用于系统内存释放
limit uintptr // 申请大对象内存块会用到,mspan的数据截止位置
......
}在这一块最主要的是理解 spanclass 和 sizeclass、span 和 object 之间的关系。
上面我们有说过,Go 的有67种大小规模,以表的形式展现,这其实就是 sizeclass。
源码文件路径:src/runtime/sizeclasses.go
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// ......
// 65 27264 81920 3 128 10.00% 128
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192sizeclass
sizeclass 中规格最小 8B,最大 32KB,显而易见这并不是针对 mspan 的规格划分(因为 mspan 最小一个页也有 8192B 的大小),这是针对 “对象” 的划分,即 Object。
object 是用来存储一个变量数据的内存空间,一个 mspan 在初始化时,会被切割成一堆等大的 object。假设 object 的大小是 16B,mspan 大小是 8KB,那么就会把 mspan 分成 512 个object;所谓内存分配,就是分配一个 object 出去。
spanclass 是用来记录 mspan 属于哪种规格类型的,具体如图:
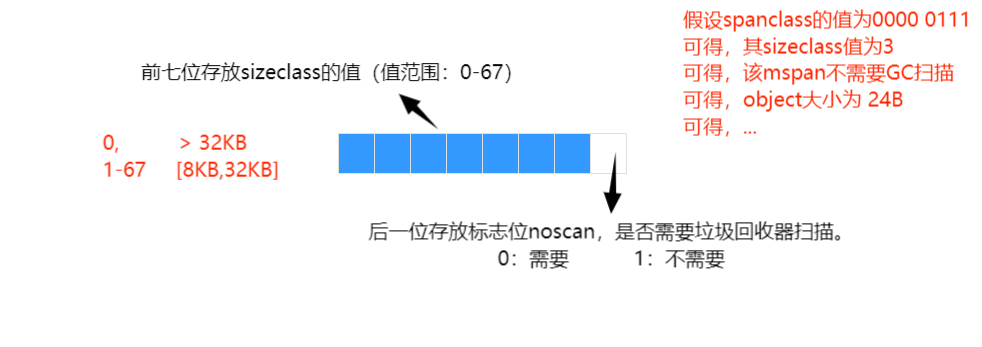
- mcache —— 是 Go 的线程缓存,它会与线程上的处理器(P)一 一 绑定,主要用来缓存用户程序申请的微小对象。
mcache有一个长度为136的 *mspan 类型的数组,在alloc字段中。
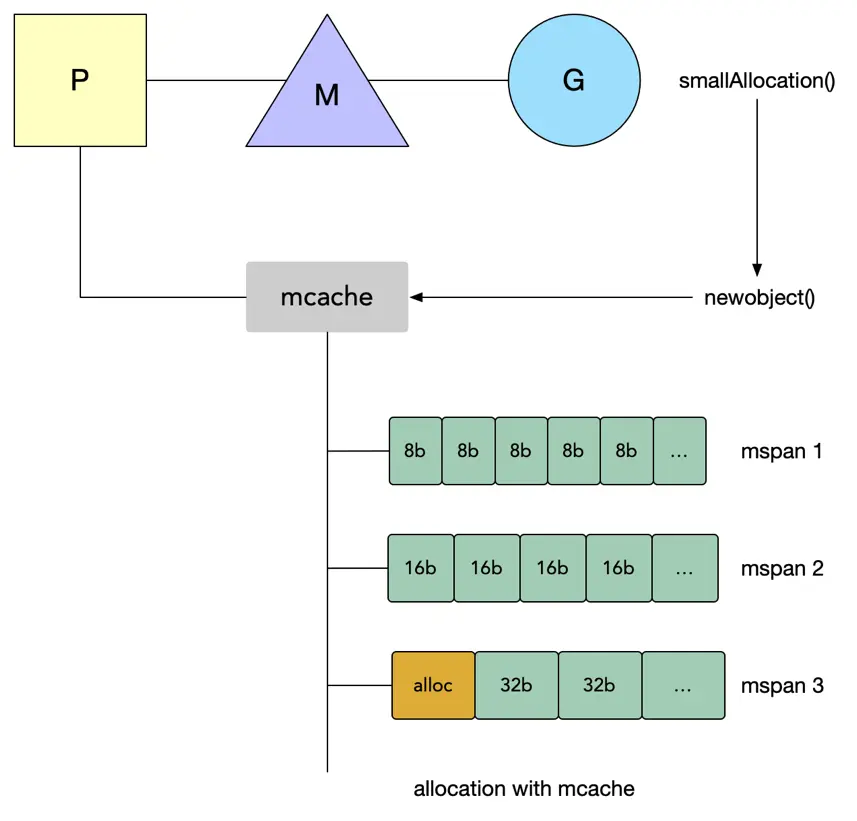
(在 Go 1.2 版本前调度器使用的是 GM 模型,将mcache 放在了 M 里,但发现存在诸多问题,期中对于内存这一块存在着巨大的浪费。每个M 都持有 mcache 和 stack alloc,但只有在 M 运行 Go 代码时才需要使用的内存(每个 mcache 可以高达2mb),当 M 在处于 syscall 或 网络请求 的时候是不需要的,再加上 M 又是允许创建多个的,这就造成了很大的浪费。所以从go 1.3版本开始使用了GPM模型,这样在高并发状态下,每个G只有在运行的时候才会使用到内存,而每个 G 会绑定一个P,所以它们在运行只占用一份 mcache,对于 mcache 的数量就是P 的数量,同时并发访问时也不会产生锁。)
源码文件路径:runtime/mchche.go Line:19
type mcache struct {
tiny uintptr //<16byte 申请小对象的起始地址
tinyoffset uintptr //从起始地址tiny开始的偏移量
local_tinyallocs uintptr //tiny对象分配的数量
alloc [numSpanClasses]*mspan // 分配的mspan list,其中numSpanClasses=68*2,索引是splanclassId
stackcache [_NumStackOrders]stackfreelist //栈缓存
local_largefree uintptr // 大对象释放字节数
local_nlargefree uintptr // 释放的大对象数量
local_nsmallfree [_NumSizeClasses]uintptr // 每种规格小对象释放的个数
flushGen uint32 //扫描计数
}mcache结构
mcache 中有三个字段组成微对象分配器,用于专门管理 16B以下的对象。微分配器只会用于分配非指针类型的内存,三个字段中 tiny 会指向堆中的一片内存,tinyoffset 是下一个空闲内存所在的偏移量,最后的 tinyAllocs 会记录内存分配器中分配的对象个数。
mcache 在初始化时是没有任何 mspan 资源的,alloc 字段中都是空的占位符 emptymspan,而是在使用过程中会动态地申请,不断地去填充 alloc[numSpanClasses]*mspan,通过双向链表连接。

- mcentral —— 是内存分配器的中心缓存,与线程缓存不同,访问中心缓存的内存管理单元需要互斥锁。
一个 mcentral 对应一种 mspan 规格类型。
当 mcache 的某个类别 span 的内存被分配光时,它会会通过中心缓存的 runtime.mcentral.cacheSpan 方法获取新的内存管理单元。
mcentral 的 partial 和 full 都有两个 spanSet 集合,这是为了给GC来使用的,一个集合是已扫描,另一个是未扫描。
源码文件路径:runtime/mcentral.go Line:21
type mcentral struct {
spanclass spanClass //对应的 spanclass
partial [2]spanSet //维护全部空闲的 span 集合
full [2]spanSet //维护存在非空闲的 span 集合
}mcentral结构
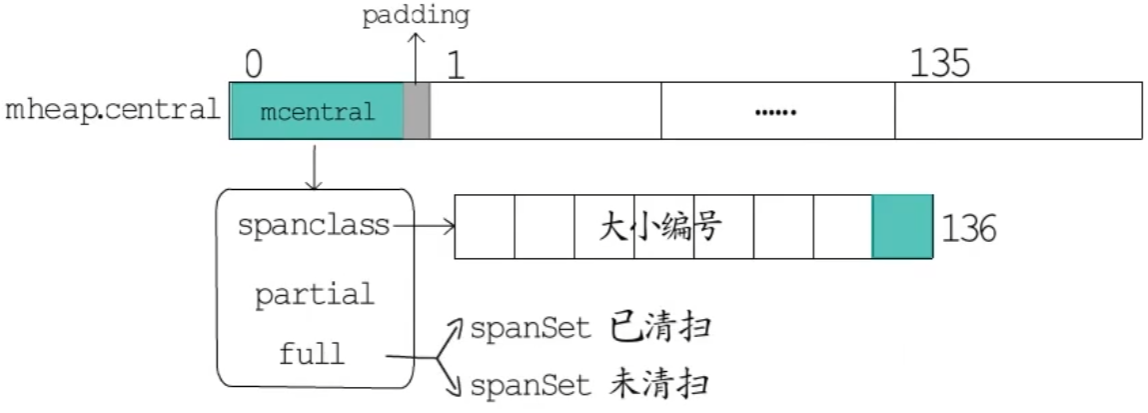
- mheap —— 管理整个堆内存。mheap 中有两组非常重要的字段,一个是 centra,全局的中心缓存列表,是一个长度为136和数组,数组元素是一个 mcentral 结构。(如上图)另一个是 **arenas,**是一组元素为 heapArena 的二维矩阵,用来管理堆区内存区域。

源码文件路径:runtime/mheap.go Line:240
type heapArena struct {
heapArenaPtrScalar // 用于标记当前这个HeapArena的内存使用情况,1. 对应地址中是否存在过对象、对象中哪些地址包含指针,2. 是否被GC标记过。主要用于GC
spans [pagesPerArena]*mspan // 存放heapArena中的span指针地址
pageInUse [pagesPerArena / 8]uint8 // 保存哪些spans处于mSpanInUse状态
pageMarks [pagesPerArena / 8]uint8 // 保存哪些spans中包含被标记的对象
pageSpecials [pagesPerArena / 8]uint8 // 保存哪些spans是特殊的
checkmarks *checkmarksMap // debug.gccheckmark state
zeroedBase uintptr //该arena第一页的第一个字节地址
}heapArena结构
heapArenaPtrScalar 是结构体,里面是原本 heapArena 的 bitmap 字段。
1个bitmap是8bit,每一个指针大小的内存都会有两个bit分别表示是否应该继续扫描和是否包含指针,这样1个byte就会对应arena区域的四个指针大小的内存。当前HeapArena中的所有Page均会被bitmap所标记,bitmap的主要作用是服务于GC垃圾回收模块。
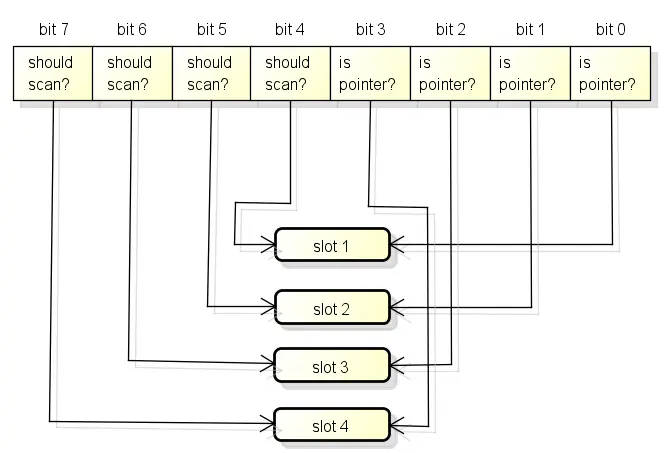
pageInUse 是一个 uint8 类型的数组,长度为1024,共8192位。这个位图用来标记处于使用状态(mSpanInUse)的 mspan 的第一个 page 。
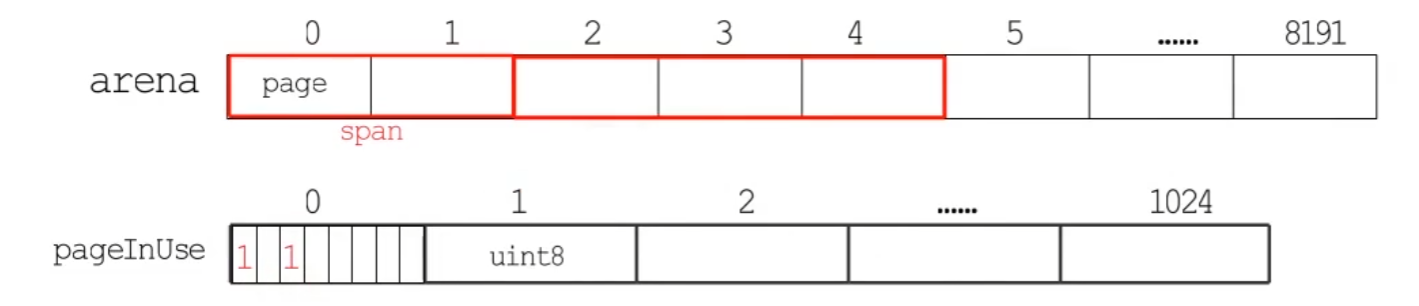
pageMarks 和上面类似,标记哪些 span 中存在被标记的对象,在GC清扫阶段会根据这个位图来释放不含标记对象的 mspan。
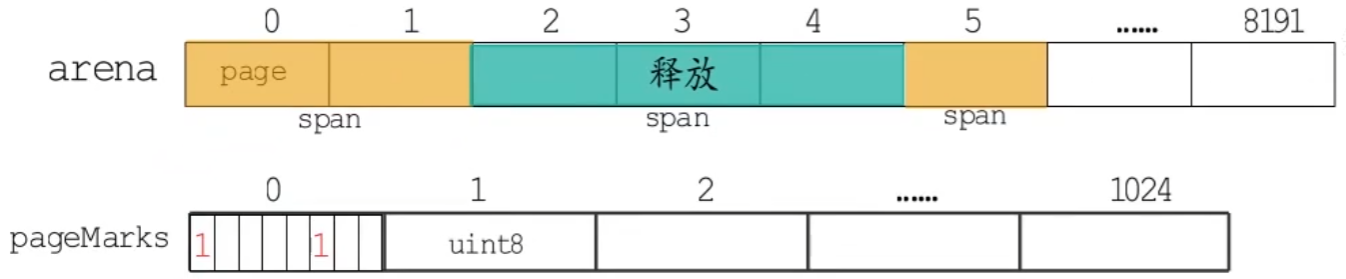
Goroutine、MCache、MCentral、MHeap互相交换的内存单位是不同,其中协程逻辑层与 mcache 的内存交换单位是 object,mcache 与 mcentral、mcentral 与 mheap 的内存交换单位是 mspan,mheap 与操作系统的内存交换单位是 page。
接下来,从宏观图示来展现上述组件之间的关联:
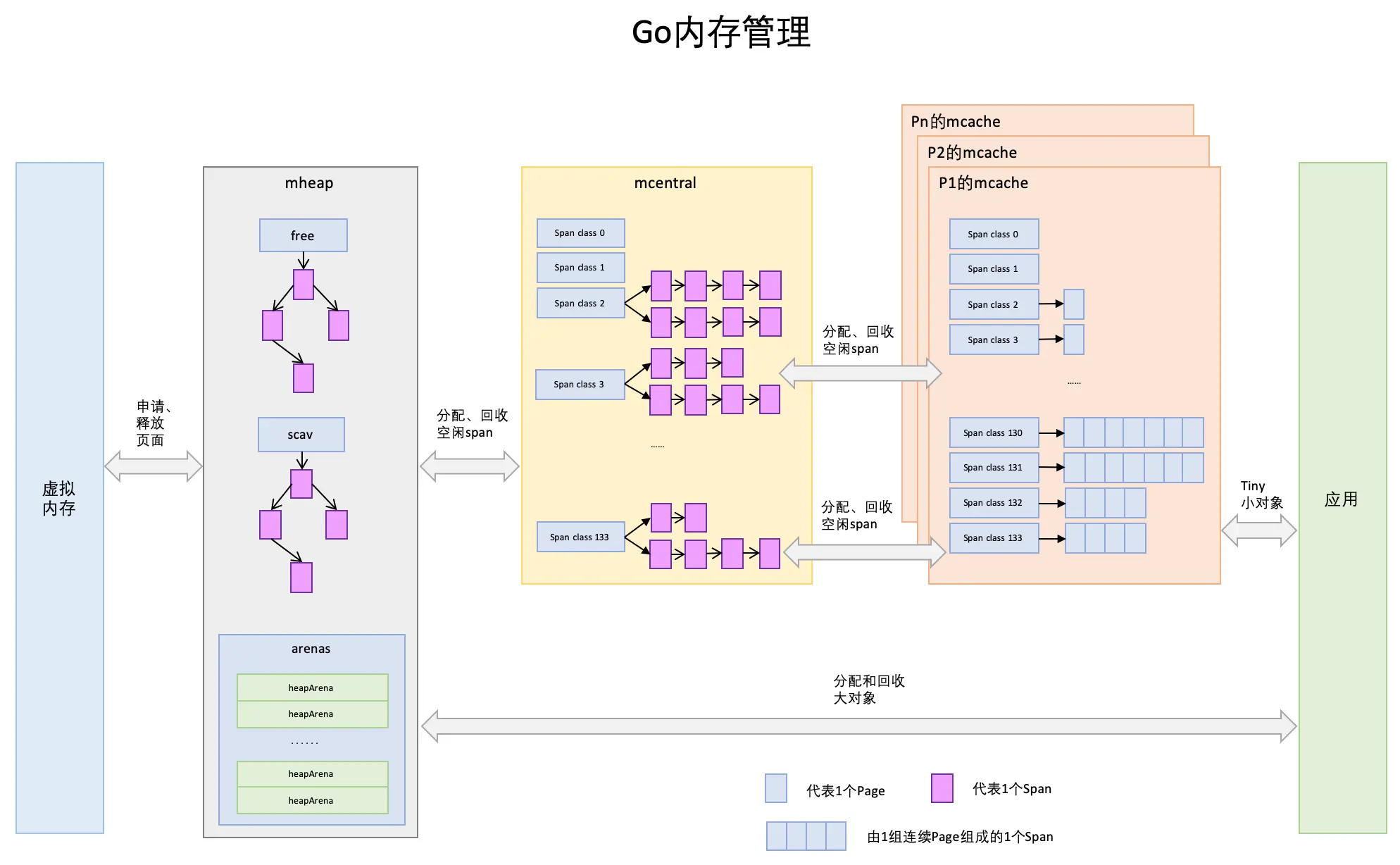
最后总结一下内存分配的流程:
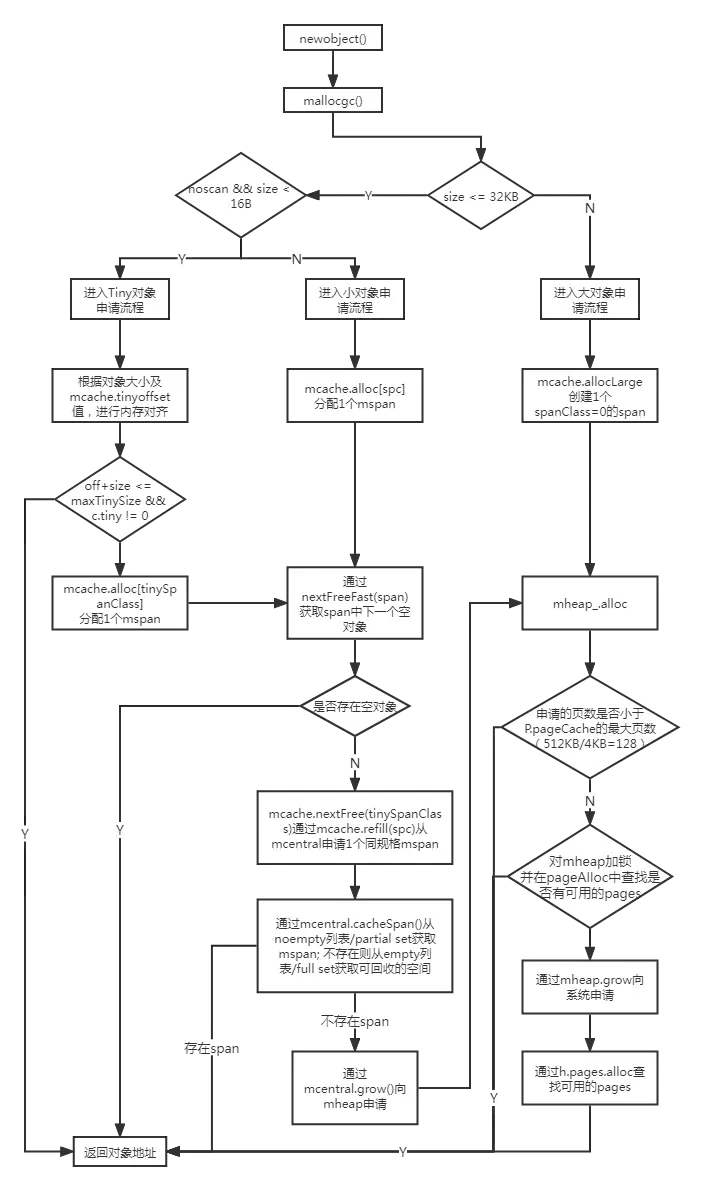
栈内存
Golang 的栈内存是在堆区里分配的内存,但其管理方式不同。
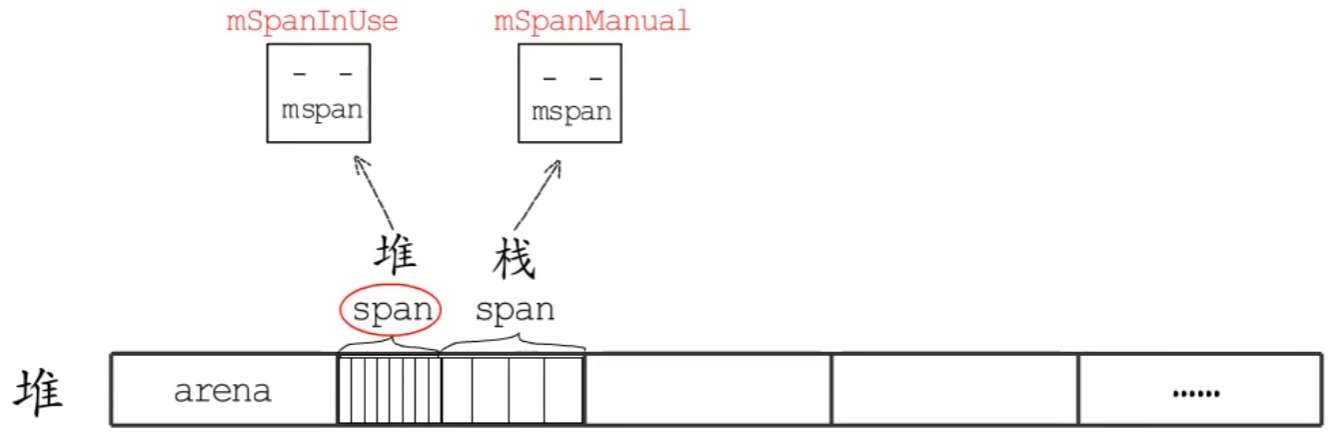
为提高栈分配效率,调度器初始化时,会初始化两个用于栈分配的全局对象:stackpool 和 stackLarge。(小于32KB使用stackopool,反之使用stackLarge)
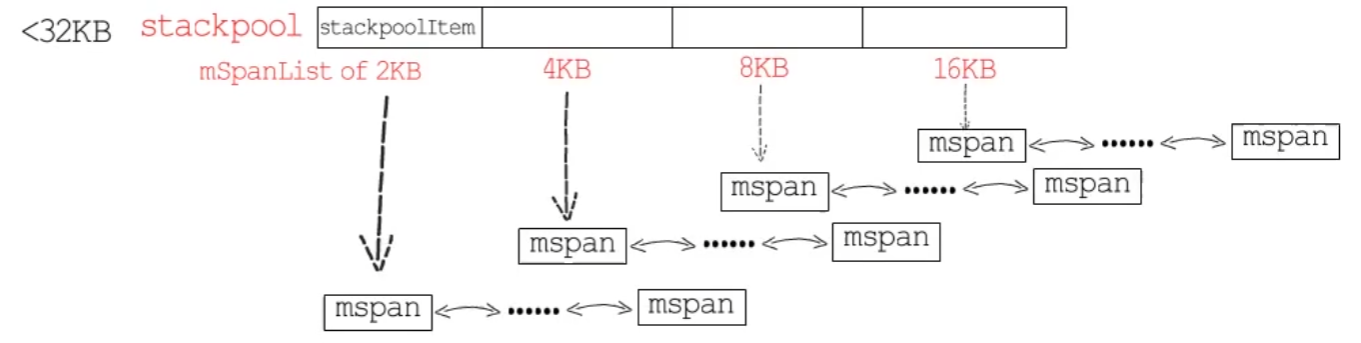

和堆内存一样,除了全局栈缓存,每个 P 也有着本地栈缓存。
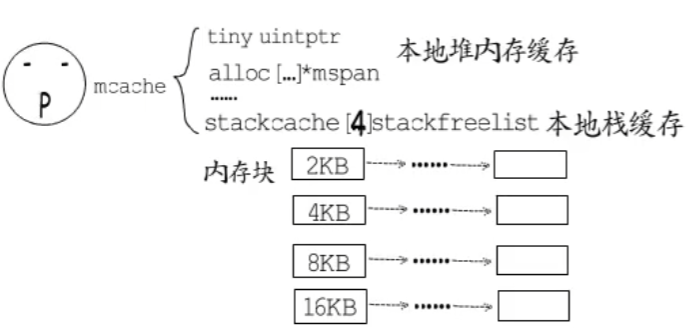
栈内存分配:
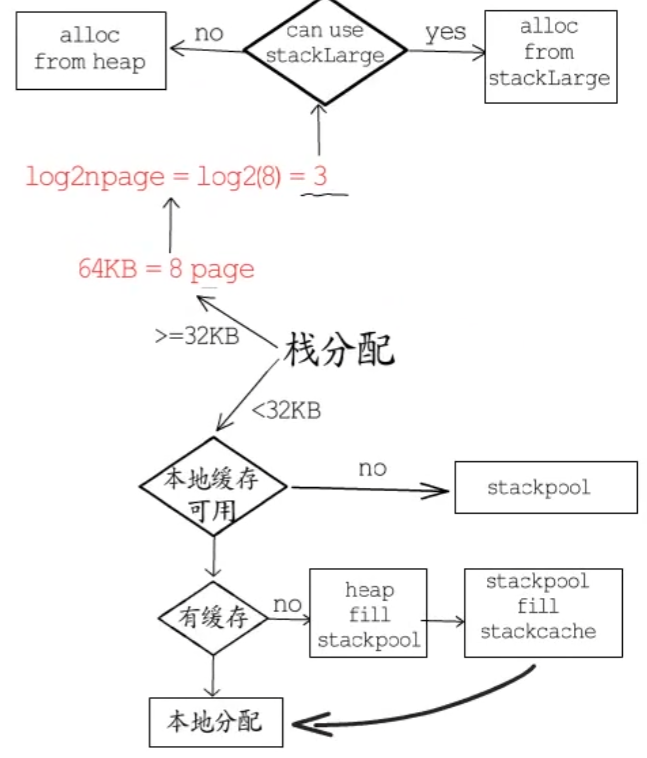
3.内存回收(GC)
Go采用的是标记清除方式。当GC开始时,从 root 开始一层层扫描,这里的root取当前所有 goroutine 的栈和全局数据区的变量(主要是这两个地方)。扫描过程中把能被触达的 object 标记出来,那么堆空间未被标记的 object 就是垃圾了(“可达性”近似等于“存活性”的思想);最后遍历堆空间所有 object 对垃圾(未标记)的object 进行清除,清除完成则表示 GC 完成。 清除的 object 会被放回到 mcache 中以备后续分配使用。
- Go1.1:全程STW(stop-the-world)
最开始时,Go的整个GC过程都需要STW,因为用户进程如果在GC过程中修改了变量的引用关系,可能导致清理错误。但这样效率低下,浪费大量时间。
- Go1.3:标记STW,清除并行
STW是为了阻止标记错误,所以只需要在标记过程进行STW即可。
- Go1.5:三色标记法
为了让标记过程也能并行,Go采用了三色标记+写屏障的机制。它的步骤如下:
- GC 开始时,认为所有 object 都是“白色”,即垃圾
- root 区的所有对象变为“灰色”
- 遍历所有“灰色”,将所有可达对象变为“灰色”,然后自身变为“黑色”
- 循环第3步,直到没有“灰色”。剩余的“黑色”是存活数据,“白色”都是垃圾
- 对于“黑色”,如果在标记期间发生了写操作,写屏障会在真正赋值前将新对象标记为“灰色”。
- 标记过程中,新分配的对象,都会变成“黑色”
还有一种情况: 标记过程中,堆上的 object 被赋值给了一个栈上指针,导致这个 object 没有被标记到。因为对栈上指针进行写入,写屏障是检测不到的(实际上并不是做不到,而是代价非常高,写屏障故意没有去管它)。下图展示了整个流程:
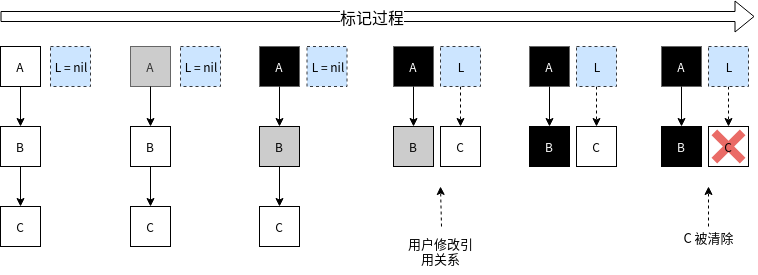
为了解决这个问题,标记的最后阶段,还会回头重新扫描一下所有的栈空间,确保没有遗漏。而这个过程就需要启动STW了,否则并发场景会使上述问题反复重现。
- Go1.8:Hibrid Write Barrier(混合写屏障)
三色标记方式,需要再最后重新扫描一遍所有全局变量和goroutie栈空间,如果系统的 goroutine 很多,这个阶段耗时也会比较长,甚至会长达 100ms。毕竟 goroutine 很轻量,大型系统中,上百万的 goroutine 也是常有的事情。
而混合写屏障,会在赋值前堆旧数据置灰,在视情况对新值进行置灰,如图所示:
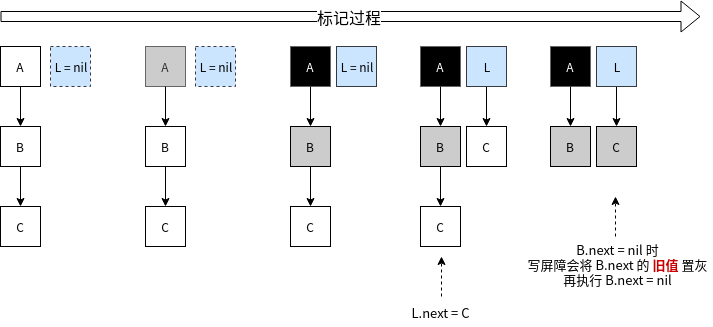
这样就不需要在最后回头重新扫描所有的 goroutine 的栈空间了,这使得整个 GC过程STW几乎可以忽略不计。
但也有一点小小的代价,就是上图中如果 C 没有赋值给 L,用户执行 B.next = nil后,C 的确变成了垃圾,而我们却把它置灰了,使得C只能等到下一轮 GC 才能被回收了。而GC 过程创建的新对象直接标记成黑色也会带来这个问题,即使新 object 在扫描结束前变成了垃圾,这次 GC 也不会回收它,只能等下轮。
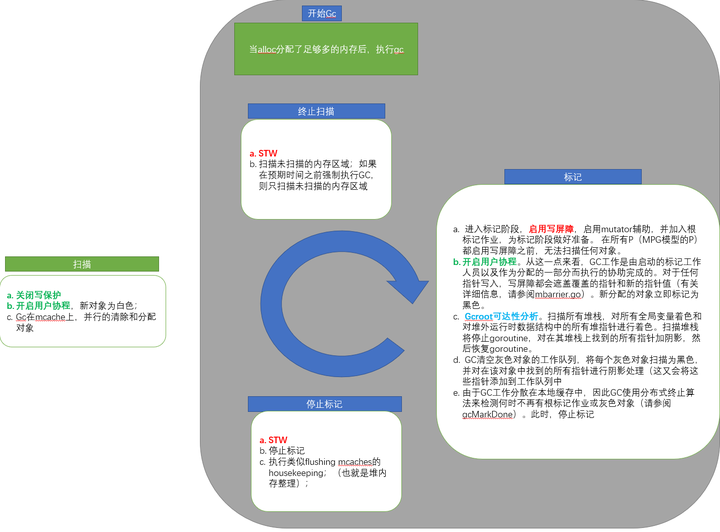
最后总结一下GC的流程图,如下:
4.函数多返回值
5.异常处理
golang不支持try...catch这样的结构化的异常解决方式。golang提倡的异常处理方式是:
- 普通异常:被调用方返回error对象,调用方判断error对象。
- 严重异常:指的是中断性panic(比如除0),使用defer...recover...panic机制来捕获处理。严重异常一般由golang内部自动抛出,不需要用户主动抛出,避免传统try...catch写得到处都是的情况。当然,用户也可以使用panic('xxxx')主动抛出,只是这样就使这一套机制退化成结构化异常机制了。
6.强类型语言
作为强类型语言,隐式的类型转换是不被golang允许的。
类型转换可以通过强制类型转换和类型断言:
当变量和指针类型不匹配时,都可以使用*type(var_name)*进行强制类型转换(如下)。
强制类型转换
package main
import (
"fmt"
"unsafe"
)
func main() {
var a float32 = 5.6
var b int = 10
//fmt.Println (a * b) //此处不能进行隐式转换
fmt.Println(a * float32(b))
var c int = 10
var p *int = &c
//var d *int64 = (*int64)(p) //指针类型的强制转换需要unsafe包
var d *int64 = (*int64)(unsafe.Pointer(p))
fmt.Println(*d)
}golang中的 interface{} 即 any 可以代表所有类型,包括基本类型string、int、int64,以及自定义的 struct 类型。因此当我们想要使用这个变量时,我们需要判断变量的类型,即进行类型断言。
- 类型断言的语法:变量b :=变量a.(类型)
断言是否正确,断言之后执行什么操作,具体实施可以通过配合 if...else 或 switch 来实现。
7.其他特性
- defer机制:在Go语言中,提供关键字defer,可以通过该关键字指定需要延迟执行的逻辑体,即在函数体return前或出现panic时执行。这种机制非常适合善后逻辑处理,比如可以尽早避免可能出现的资源泄漏问题。
- 编程规范:GO语言的编程规范强制集成在语言中,比如明确规定花括号摆放位置,强制要求一行一句,不允许导入没有使用的包,不允许定义没有使用的变量,提供gofmt工具强制格式化代码等等。
- “包”的概念:和python一样,把相同功能的代码放到一个目录,称之为包。包可以被其他包引用。main包是用来生成可执行文件,每个程序只有一个main包。包的主要用途是提高代码的可复用性。通过package可以引入其他包。