

函数进阶
1.函数调用栈
函数栈帧
分配给函数的栈空间被称为**函数栈帧。**其大致布局如下图所示:
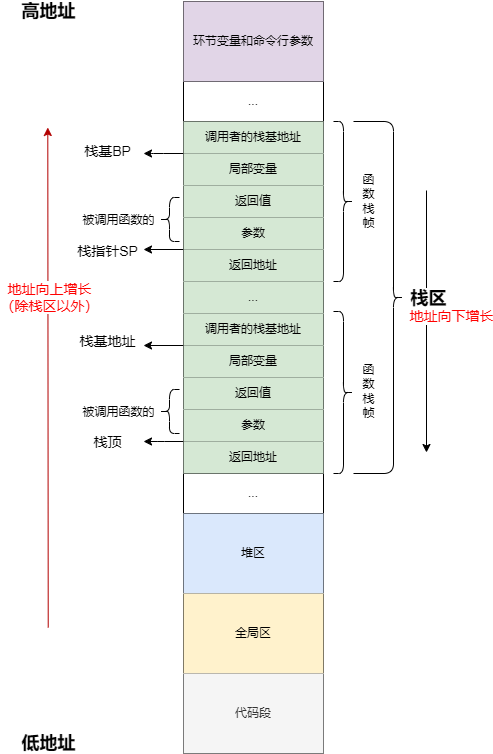
- 调用者的栈基地址:保存调用函数的栈基地址,用于函数返回后获得调用函数的栈帧基地址
- 局部变量:函数内部本地变量
- 返回值:保存函数返回值临时变量
- 参数:函数调用时传入的参数,其值会被复制到函数栈帧中的参数变量中
- 返回地址:保存被调用函数返回后的程序地址,即调用函数中的下一条指令
- BP、SP寄存器:保存当前函数的栈基地址和栈指针
注意:被调用函数的参数和返回值,是在调用者的函数栈帧中,而不是 被调用函数 的函数栈帧中
在 Go 语言中,是通过栈指针SP + 偏移来定位每个参数和返回值,因为 Go 的函数栈帧是一次性分配的 —— 分配栈帧时,直接将栈指针移到所需最大栈空间的位置,也就是栈顶。
一次性分配是为了防止栈访问越界。Go 语言编译器会在函数头部插入检测代码,如果发现需要进行“栈增长”,就会另外分配足够大的栈空间,把原来栈上的数据拷贝过来,原来的栈空间就会被释放。
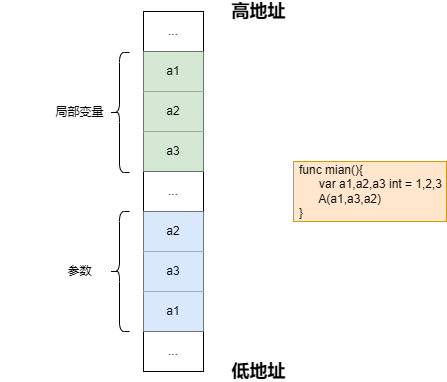
传参
参数入栈顺序:从右至左,也就是从最后一个参数开始入栈,到第一个参数最后入栈
返回值
上一篇有提到返回值命名后,无论怎样,都会返回所命名的变量。通过函数栈帧能够非常清晰的了解其发生的具体原因:
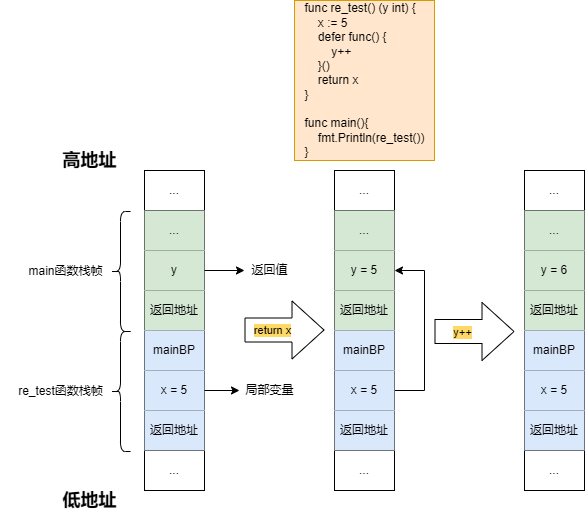
即便没有进行返回值命名,编译器也会为返回值取名(例如:~r0、~r1...),可以说是独特的变量。
调用分析
在调用分析前,先了解两个函数调用时非常重要的汇编指令:
Call 指令:函数调用时,编译器会执行Call指令
- 将下一条指令的地址入栈,被调用函数结束后,跳回到该地址继续执行,这就是返回地址
- 跳转到被调用函数的指令入口处执行
Ret 指令**:函数返回时**,编译器会执行Ret指令
- 弹出Call 指令压栈的返回地址
- 跳转到返回地址
例一:
package main
import "fmt"
func B(a, b int) int {
return a + b
}
func A(x, y int) int {
z := B(x, y)
return z
}
func main() {
var a,b int = 6,8
c := A(a,b)
fmt.Println(c)
}main函数:
var a,b int = 6,8
MOVQ $0x6 ,0x40(SP)
MOVQ $0x8 ,0x38(SP)c := A(a,b)
MOVQ 0x40(SP), AX
MOVQ AX, 0(SP)
MOVQ $0x8,0x8(SP)
CALL $main.A(SB)
MOVQ 0x10(SP), AX
MOVQ AX, 0x30(SP)执行到CALL指令时,函数调用栈如下:

A 函数:
func A(x, y int) int {
MOVQ GS:0x28, CX
MOVQ 0(CX),CX
CMPQ SP, 0x10(CX)
JBE $0x6f63e0
SUBQ $0x28, SP //SP向下移动0x28,这是A的函数栈帧大小
MOVQ BP, 0x20(SP) //存main的BP
LEAQ 0x20(SP), BP //设置A的BP
MOVQ $0x0, 0x40(SP) //初始化返回值,置0z := B(x, y)
MOVQ 0x38(SP), AX
MOVQ 0x30(SP), CX
MOVQ CX, 0(SP)
MOVQ AX, 0x8(SP)
CALL $main.B(SB)
MOVQ 0x10(SP), AX
MOVQ AX, 0x18(SP)执行到CALL指令时,函数调用栈如下:
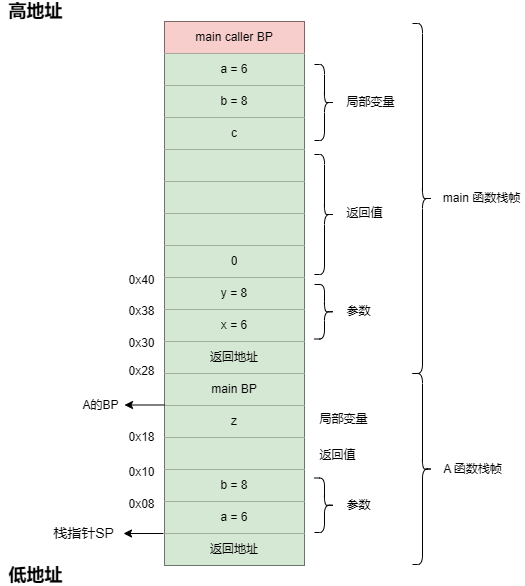
B函数:
func B(a, b int) int {
return a + b
MOVQ 0x8(SP), AX
ADDQ 0x10(SP), AX
MOVQ AX, 0x18(SP)
RET从汇编代码可以看出,编译器没有为B函数分配函数栈帧,这是因为B函数没有局部变量,也没有调用其他函数。运行到RET时,函数调用栈如下:
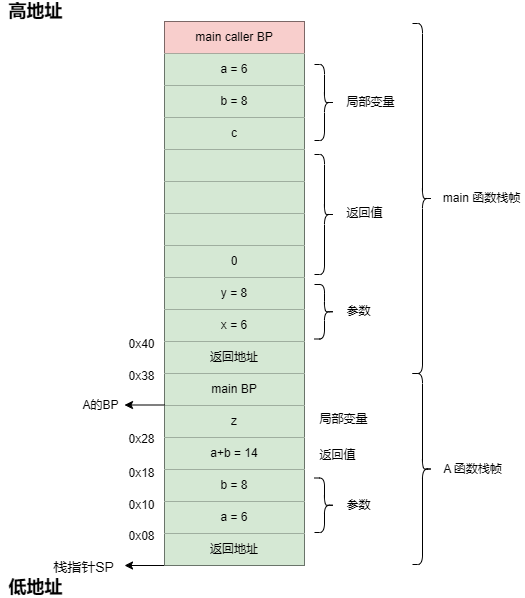
(注意:执行了call指令后,SP会向下移动,指向返回地址。)
接下来就是逐步返回,函数调用栈如下:

看到这,可能会有一个疑问:
main 函数栈帧中,返回值区域只用了一个内存块,为什么要分配那么大空间?
那是因为 Go 是一次性分配的,所以会分配所需要的最大空间。虽然调用的A函数只用了一块,但之后的 fmt.Println 函数会用到这些空间。只不过在这里,我们并不对 fmt.Println 函数进行分析。
新版函数调用栈
上面的例子是靠栈区传递参数和返回值,是Go早期版本的统一标准,但在 Go 1.17 后,开始支持寄存器传递参数和返回值,函数调用栈就有所不同了:
一、 函数返回值由函数自己的函数栈帧保存。(原本是由调用者的函数栈帧保存)
二、 9个以内的参数或返回值,由寄存器传递;9个以外的通过栈传递。
三、 栈基地址 指向 保存返回地址的栈空间(原本是指向 保存调用者的栈基地址的栈空间 )
四、 返回地址由被调用者的函数栈帧保存(因为被调用者的栈基地址指向了它)
例二
package main
func A(p1, p2, p3, p4, p5, p6, p7, p8, p9, p10, p11 int64) (int64, int64) {
return p1 + p2 + p3 + p4 + p5 + p6 + p7, p2 + p4 + p6 + p7 + p8 + p9 + p10 + p11
}
func main() {
var r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11 int64 = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
a, b := A(r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11)
c := a + b
print(c)
}其他步骤和原来一样,就不逐步分析了,函数调用栈如下:

在上图中,可以看到局部变量有很多个a、b,编译器为什么要这么做?具体原因笔者并不清楚,下面放对应的汇编代码:
a, b := A(r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11)
MOVQ 0xa8(SP), AX
MOVQ 0x68(SP), R9
MOVQ 0x70(SP), R8
MOVQ 0x78(SP), SI
MOVQ 0x80(SP), DI
MOVQ 0x88(SP), CX
MOVQ 0x90(SP), BX
MOVQ $0xa, 0(SP)
MOVQ $0xb, 0x8(SP) //上面和这里都是寄存器传参
MOVL $0x8 ,R10
MOVL $0x9 ,R11 //这两步是栈区传参
NOPL 0(AX)(AX*1)
CALL $main.A(SB) //调用A函数,第一个返回值存在AX中,第二个存在BX中
MOVQ AX, 0xd0(SP)
MOVQ BX, 0xc8(SP)
MOVQ AX, 0xe0(SP)
MOVQ BX, 0xd8(SP)
MOVQ AX, 0xc0(SP)
MOVQ BX, 0xb8(SP) //返回值存入局部变量中2.闭包
在 Go 语言中,函数被当做一种变量 Function Value,本质上是一个指针,指向 runtime.funcval 结构体,这个结构体保存了函数的入口地址 fn uintptr。
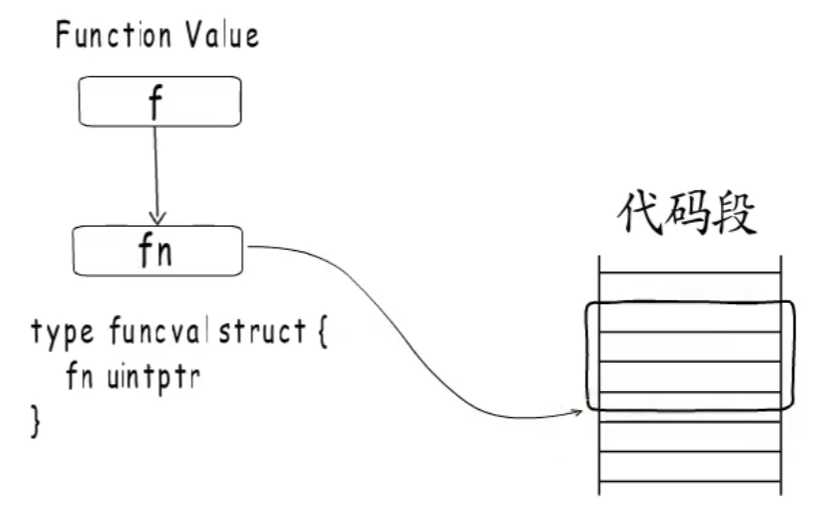
Go 在编译期间会将创建捕获列表加入到 funcval 结构体中实现闭包。
闭包在源码中的具体实现待有空在详细了解,这里只分析闭包在不同情况的表现:
不修改捕获变量
不修改捕获变量的闭包,创建捕获列表时,只会单纯地进行值拷贝:
修改捕获变量
修改捕获变量的闭包,创建捕获列表和 funcval 结构体前,会先为捕获变量分配堆内存(变量逃逸),而捕获列表中是指向捕获变量的指针:
闭包小结
一、Function Value 本质上是指向 funcval 结构体的指针;
二、闭包是拥有捕获列表的 Function Value;
三、闭包可能会引发变量逃逸。