

一、预处理器(Preprocessor)
简介
C 语言编译器在编译程序之前,会先使用预处理器(preprocessor)处理代码。
预处理器首先会清理代码,进行删除注释、多行语句合成一个逻辑行等工作。然后,执行#开头的预处理指令。本章介绍 C 语言的预处理指令。
预处理指令可以出现在程序的任何地方,但是习惯上,往往放在代码的开头部分。
每个预处理指令都以#开头,放在一行的行首,指令前面可以有空白字符(比如空格或制表符)。#和指令的其余部分之间也可以有空格,但是为了兼容老的编译器,一般不留空格。
所有预处理指令都是一行的,除非在行尾使用反斜杠,将其折行。指令结尾处不需要分号。
#define
#define是最常见的预处理指令,用来将指定的词替换成另一个词。它的参数分成两个部分,第一个参数就是要被替换的部分,其余参数是替换后的内容。每条替换规则,称为一个宏(macro)。
#define MAX 100上面示例中,#define指定将源码里面的MAX,全部替换成100。MAX就称为一个宏。
宏的名称不允许有空格,而且必须遵守 C 语言的变量命名规则,只能使用字母、数字与下划线(_),且首字符不能是数字。
宏是原样替换,指定什么内容,就一模一样替换成什么内容。
#define HELLO "Hello, world"
// 相当于 printf("%s", "Hello, world");
printf("%s", HELLO);上面示例中,宏HELLO会被原样替换成"Hello, world"。
#define指令可以出现在源码文件的任何地方,从指令出现的地方到文件末尾都有效。习惯上,会将#define放在源码文件的头部。它的主要好处是,会使得程序的可读性更好,也更容易修改。
#define指令从#开始,一直到换行符为止。如果整条指令过长,可以在折行处使用反斜杠,延续到下一行。
#define OW "C programming language is invented \
in 1970s."上面示例中,第一行结尾的反斜杠将#define指令拆成两行。
#define允许多重替换,即一个宏可以包含另一个宏。
#define TWO 2
#define FOUR TWO*TWO上面示例中,FOUR会被替换成2*2。
注意,如果宏出现在字符串里面(即出现在双引号中),或者是其他标识符的一部分,就会失效,并不会发生替换。
#define TWO 2
// 输出 TWO
printf("TWO\n");
// 输出 22
const TWOs = 22;
printf("%d\n", TWOs);上面示例中,双引号里面的TWO,以及标识符TWOs,都不会被替换。
同名的宏可以重复定义,只要定义是相同的,就没有问题。如果定义不同,就会报错。
// 正确
#define FOO hello
#define FOO hello
// 报错
#define BAR hello
#define BAR world上面示例中,宏FOO没有变化,所以可以重复定义,宏BAR发生了变化,就报错了。
带参数的宏
基本用法
宏的强大之处在于,它的名称后面可以使用括号,指定接受一个或多个参数。
#define SQUARE(X) X*X上面示例中,宏SQUARE可以接受一个参数X,替换成X*X。
注意,宏的名称与左边圆括号之间,不能有空格。
这个宏的用法如下。
// 替换成 z = 2*2;
z = SQUARE(2);这种写法很像函数,但又不是函数,而是完全原样的替换,会跟函数有不一样的行为。
#define SQUARE(X) X*X
// 输出19
printf("%d\n", SQUARE(3 + 4));上面示例中,SQUARE(3 + 4)如果是函数,输出的应该是 49(7*7);宏是原样替换,所以替换成3 + 4*3 + 4,最后输出 19。
可以看到,原样替换可能导致意料之外的行为。解决办法就是在定义宏的时候,尽量多使用圆括号,这样可以避免很多意外。
#define SQUARE(X) ((X) * (X))上面示例中,SQUARE(X)替换后的形式,有两层圆括号,就可以避免很多错误的发生。
宏的参数也可以是空的。
#define getchar() getc(stdin)上面示例中,宏getchar()的参数就是空的。这种情况其实可以省略圆括号,但是加上了,会让它看上去更像函数。
一般来说,带参数的宏都是一行的。下面是两个例子。
#define MAX(x, y) ((x)>(y)?(x):(y))
#define IS_EVEN(n) ((n)%2==0)如果宏的长度过长,可以使用反斜杠(\)折行,将宏写成多行。
#define PRINT_NUMS_TO_PRODUCT(a, b) { \
int product = (a) * (b); \
for (int i = 0; i < product; i++) { \
printf("%d\n", i); \
} \
}上面示例中,替换文本放在大括号里面,这是为了创造一个块作用域,避免宏内部的变量污染外部。
带参数的宏也可以嵌套,一个宏里面包含另一个宏。
#define QUADP(a, b, c) ((-(b) + sqrt((b) * (b) - 4 * (a) * (c))) / (2 * (a)))
#define QUADM(a, b, c) ((-(b) - sqrt((b) * (b) - 4 * (a) * (c))) / (2 * (a)))
#define QUAD(a, b, c) QUADP(a, b, c), QUADM(a, b, c)上面示例是一元二次方程组求解的宏,由于存在正负两个解,所以宏QUAD先替换成另外两个宏QUADP和QUADM,后者再各自替换成一个解。
那么,什么时候使用带参数的宏,什么时候使用函数呢?
一般来说,应该首先使用函数,它的功能更强、更容易理解。宏有时候会产生意想不到的替换结果,而且往往只能写成一行,除非对换行符进行转义,但是可读性就变得很差。
宏的优点是相对简单,本质上是字符串替换,不涉及数据类型,不像函数必须定义数据类型。而且,宏将每一处都替换成实际的代码,省掉了函数调用的开销,所以性能会好一些。另外,以前的代码大量使用宏,尤其是简单的数学运算,为了读懂前人的代码,需要对它有所了解。
#运算符,##运算符
由于宏不涉及数据类型,所以替换以后可能为各种类型的值。如果希望替换后的值为字符串,可以在替换文本的参数前面加上#。
#define STR(x) #x
// 等同于 printf("%s\n", "3.14159");
printf("%s\n", STR(3.14159));上面示例中,STR(3.14159)会被替换成3.14159。如果x前面没有#,这会被解释成一个浮点数,有了#以后,就会被转换成字符串。
下面是另一个例子。
#define XNAME(n) "x"#n
// 输出 x4
printf("%s\n", XNAME(4));上面示例中,#n指定参数输出为字符串,再跟前面的字符串结合,最终输出为"x4"。如果不加#,这里实现起来就很麻烦了。
如果替换后的文本里面,参数需要跟其他标识符连在一起,组成一个新的标识符,可以使用##运算符。它起到粘合作用,将参数“嵌入”一个标识符之中。
#define MK_ID(n) i##n上面示例中,n是宏MK_ID的参数,这个参数需要跟标识符i粘合在一起,这时i和n之间就要使用##运算符。下面是这个宏的用法示例。
int MK_ID(1), MK_ID(2), MK_ID(3);
// 替换成
int i1, i2, i3;上面示例中,替换后的文本i1、i2、i3是三个标识符,参数n是标识符的一部分。从这个例子可以看到,##运算符的一个主要用途是批量生成变量名和标识符。
不定参数的宏
宏的参数还可以是不定数量的(即不确定有多少个参数),...表示剩余的参数。
#define X(a, b, ...) (10*(a) + 20*(b)), __VA_ARGS__上面示例中,X(a, b, ...)表示X()至少有两个参数,多余的参数使用...表示。在替换文本中,__VA_ARGS__代表多余的参数(每个参数之间使用逗号分隔)。下面是用法示例。
X(5, 4, 3.14, "Hi!", 12)
// 替换成
(10*(5) + 20*(4)), 3.14, "Hi!", 12注意,...只能替代宏的尾部参数,不能写成下面这样。
// 报错
#define WRONG(X, ..., Y) #X #__VA_ARGS__ #Y上面示例中,...替代中间部分的参数,这是不允许的,会报错。
__VA_ARGS__前面加上一个#号,可以让输出变成一个字符串。
#define X(...) #__VA_ARGS__
printf("%s\n", X(1,2,3)); // Prints "1, 2, 3"#undef
#undef指令用来取消已经使用#define定义的宏。
#define LIMIT 400
#undef LIMIT上面示例的undef指令取消已经定义的宏LIMIT,后面就可以重新用 LIMIT 定义一个宏。
有时候想重新定义一个宏,但不确定是否以前定义过,就可以先用#undef取消,然后再定义。因为同名的宏如果两次定义不一样,会报错,而#undef的参数如果是不存在的宏,并不会报错。
GCC 的-U选项可以在命令行取消宏的定义,相当于#undef。
$ gcc -ULIMIT foo.c上面示例中的-U参数,取消了宏LIMIT,相当于源文件里面的#undef LIMIT。
#include
#include指令用于编译时将其他源码文件,加载进入当前文件。它有两种形式。
// 形式一
#include <foo.h> // 加载系统提供的文件
// 形式二
#include "foo.h" // 加载用户提供的文件形式一,文件名写在尖括号里面,表示该文件是系统提供的,通常是标准库的库文件,不需要写路径。因为编译器会到系统指定的安装目录里面,去寻找这些文件。
形式二,文件名写在双引号里面,表示该文件由用户提供,具体的路径取决于编译器的设置,可能是当前目录,也可能是项目的工作目录。如果所要包含的文件在其他位置,就需要指定路径,下面是一个例子。
#include "/usr/local/lib/foo.h"GCC 编译器的-I参数,也可以用来指定include命令中用户文件的加载路径。
$ gcc -Iinclude/ -o code code.c上面命令中,-Iinclude/指定从当前目录的include子目录里面,加载用户自己的文件。
#include最常见的用途,就是用来加载包含函数原型的头文件(后缀名为.h),参见《多文件编译》一章。多个#include指令的顺序无关紧要,多次包含同一个头文件也是合法的。
#if...#endif
#if...#endif指令用于预处理器的条件判断,满足条件时,内部的行会被编译,否则就被编译器忽略。
#if 0
const double pi = 3.1415; // 不会执行
#endif上面示例中,#if后面的0,表示判断条件不成立。所以,内部的变量定义语句会被编译器忽略。#if 0这种写法常用来当作注释使用,不需要的代码就放在#if 0里面。
#if后面的判断条件,通常是一个表达式。如果表达式的值不等于0,就表示判断条件为真,编译内部的语句;如果表达式的值等于 0,表示判断条件为伪,则忽略内部的语句。
#if...#endif之间还可以加入#else指令,用于指定判断条件不成立时,需要编译的语句。
#define FOO 1
#if FOO
printf("defined\n");
#else
printf("not defined\n");
#endif上面示例中,宏FOO如果定义过,会被替换成1,从而输出defined,否则输出not defined。
如果有多个判断条件,还可以加入#elif命令。
#if HAPPY_FACTOR == 0
printf("I'm not happy!\n");
#elif HAPPY_FACTOR == 1
printf("I'm just regular\n");
#else
printf("I'm extra happy!\n");
#endif上面示例中,通过#elif指定了第二重判断。注意,#elif的位置必须在#else之前。如果多个判断条件皆不满足,则执行#else的部分。
没有定义过的宏,等同于0。因此如果UNDEFINED是一个没有定义过的宏,那么#if UNDEFINED为伪,而#if !UNDEFINED为真。
#if的常见应用就是打开(或关闭)调试模式。
#define DEBUG 1
#if DEBUG
printf("value of i : %d\n", i);
printf("value of j : %d\n", j);
#endif上面示例中,通过将DEBUG设为1,就打开了调试模式,可以输出调试信息。
GCC 的-D参数可以在编译时指定宏的值,因此可以很方便地打开调试开关。
$ gcc -DDEBUG=1 foo.c上面示例中,-D参数指定宏DEBUG为1,相当于在代码中指定#define DEBUG 1。
#ifdef...#endif
#ifdef...#endif指令用于判断某个宏是否定义过。
有时源码文件可能会重复加载某个库,为了避免这种情况,可以在库文件里使用#define定义一个空的宏。通过这个宏,判断库文件是否被加载了。
#define EXTRA_HAPPY上面示例中,EXTRA_HAPPY就是一个空的宏。
然后,源码文件使用#ifdef...#endif检查这个宏是否定义过。
#ifdef EXTRA_HAPPY
printf("I'm extra happy!\n");
#endif上面示例中,#ifdef检查宏EXTRA_HAPPY是否定义过。如果已经存在,表示加载过库文件,就会打印一行提示。
#ifdef可以与#else指令配合使用。
#ifdef EXTRA_HAPPY
printf("I'm extra happy!\n");
#else
printf("I'm just regular\n");
#endif上面示例中,如果宏EXTRA_HAPPY没有定义过,就会执行#else的部分。
#ifdef...#else...#endif可以用来实现条件加载。
#ifdef MAVIS
#include "foo.h"
#define STABLES 1
#else
#include "bar.h"
#define STABLES 2
#endif上面示例中,通过判断宏MAVIS是否定义过,实现加载不同的头文件。
defined 运算符
上一节的#ifdef指令,等同于#if defined。
#ifdef FOO
// 等同于
#if defined FOO上面示例中,defined是一个预处理运算符,如果它的参数是一个定义过的宏,就会返回 1,否则返回 0。
使用这种语法,可以完成多重判断。
#if defined FOO
x = 2;
#elif defined BAR
x = 3;
#endif这个运算符的一个应用,就是对于不同架构的系统,加载不同的头文件。
#if defined IBMPC
#include "ibmpc.h"
#elif defined MAC
#include "mac.h"
#else
#include "general.h"
#endif上面示例中,不同架构的系统需要定义对应的宏。代码根据不同的宏,加载对应的头文件。
#ifndef...#endif
#ifndef...#endif指令跟#ifdef...#endif正好相反。它用来判断,如果某个宏没有被定义过,则执行指定的操作。
#ifdef EXTRA_HAPPY
printf("I'm extra happy!\n");
#endif
#ifndef EXTRA_HAPPY
printf("I'm just regular\n");
#endif上面示例中,针对宏EXTRA_HAPPY是否被定义过,#ifdef和#ifndef分别指定了两种情况各自需要编译的代码。
#ifndef常用于防止重复加载。举例来说,为了防止头文件myheader.h被重复加载,可以把它放在#ifndef...#endif里面加载。
#ifndef MYHEADER_H
#define MYHEADER_H
#include "myheader.h"
#endif上面示例中,宏MYHEADER_H对应文件名myheader.h的大写。只要#ifndef发现这个宏没有被定义过,就说明该头文件没有加载过,从而加载内部的代码,并会定义宏MYHEADER_H,防止被再次加载。
#ifndef等同于#if !defined。
#ifndef FOO
// 等同于
#if !defined FOO预定义宏
C 语言提供一些预定义的宏,可以直接使用。
__DATE__:编译日期,格式为“Mmm dd yyyy”的字符串(比如 Nov 23 2021)。__TIME__:编译时间,格式为“hh:mm:ss”。__FILE__:当前文件名。__LINE__:当前行号。__func__:当前正在执行的函数名。该预定义宏必须在函数作用域使用。__STDC__:如果被设为 1,表示当前编译器遵循 C 标准。__STDC_HOSTED__:如果被设为 1,表示当前编译器可以提供完整的标准库;否则被设为 0(嵌入式系统的标准库常常是不完整的)。__STDC_VERSION__:编译所使用的 C 语言版本,是一个格式为yyyymmL的长整数,C99 版本为“199901L”,C11 版本为“201112L”,C17 版本为“201710L”。
下面示例打印这些预定义宏的值。
#include <stdio.h>
int main(void) {
printf("This function: %s\n", __func__);
printf("This file: %s\n", __FILE__);
printf("This line: %d\n", __LINE__);
printf("Compiled on: %s %s\n", __DATE__, __TIME__);
printf("C Version: %ld\n", __STDC_VERSION__);
}
/* 输出如下
This function: main
This file: test.c
This line: 7
Compiled on: Mar 29 2021 19:19:37
C Version: 201710
*/#line
#line指令用于覆盖预定义宏__LINE__,将其改为自定义的行号。后面的行将从__LINE__的新值开始计数。
// 将下一行的行号重置为 300
#line 300上面示例中,紧跟在#line 300后面一行的行号,将被改成 300,其后的行会在 300 的基础上递增编号。
#line还可以改掉预定义宏__FILE__,将其改为自定义的文件名。
#line 300 "newfilename"上面示例中,下一行的行号重置为300,文件名重置为newfilename。
#error
#error指令用于让预处理器抛出一个错误,终止编译。
#if __STDC_VERSION__ != 201112L
#error Not C11
#endif上面示例指定,如果编译器不使用 C11 标准,就中止编译。GCC 编译器会像下面这样报错。
$ gcc -std=c99 newish.c
newish.c:14:2: error: #error Not C11上面示例中,GCC 使用 C99 标准编译,就报错了。
#if INT_MAX < 100000
#error int type is too small
#endif上面示例中,编译器一旦发现INT类型的最大值小于100,000,就会停止编译。
#error指令也可以用在#if...#elif...#else的部分。
#if defined WIN32
// ...
#elif defined MAC_OS
// ...
#elif defined LINUX
// ...
#else
#error NOT support the operating system
#endif#pragma
#pragma指令用来修改编译器属性。
// 使用 C99 标准
#pragma c9x on上面示例让编译器以 C99 标准进行编译。
二、gcc 编译器介绍
gcc 命令 使用 GNU 推出的基于 C/C++ 的编译器,是开放源代码领域应用最广泛的编译器,具有功能强大,编译代码支持性能优化等特点。现在很多程序员都应用 GCC,怎样才能更好的应用 GCC。目前,GCC 可以用来编译 C/C++、FORTRAN、JAVA、OBJC、ADA等语言的程序,可根据需要选择安装支持的语言。
gcc 的工作流程
gcc 编译器将 C 源文件到生成一个可执行程序,中间一共经历了四个步骤:

四个步骤并不是 gcc 独立完成的,而是在内部调用了其他工具,从而完成了整个工作流程,其中编译最耗时,因为要逐行检查语法。
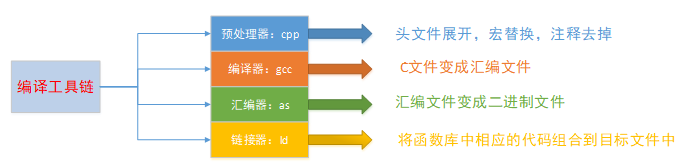
- 预处理
cpp 预处理器、去掉注释、展开头文件、宏替换
**注意:**在此步骤,没有进行语法检查
gcc -E test.c -o test.i- 编译
gcc,将源代码文件编译成汇编语言代码
**注意:**在此步骤,进行了语法检查
gcc -S test.i -o test.s- 汇编
as,将汇编语言代码编译成二进制文件
gcc -c test.s -o test.o- 链接
ld,链接 test.c 代码中调用的库函数
gcc test.o -o test 一步生成最终的可执行程序:
gcc test.c -o testgcc 常用参数介绍
-v: 查看gcc版本号, --version也可以
-o:指定生成的输出文件;
-E:仅执行编译预处理;
-S:将C代码转换为汇编代码;
-wall:显示警告信息;
-c:仅执行编译操作,不进行连接操作。
-l:用来指定程序要链接的库,-l参数紧接着就是库名
-I:寻找头文件的目录
-L: 指定库文件所在的路径
-g: 包含调试信息, 使用gdb调试需要添加-g参数https://wangchujiang.com/linux-command/c/gcc.html